A.I.
Effective AI inferencing for embedded systems

MANAGEMENT

ACTIVATED
ASSISTANTS

LIGHTING

SYSTEMS

HVAC

MAINTENANCE
Key features
 Programmable Performance
Programmable Performance
- 256-bit vector processing unit with 100GOPS int-8 AI inferencing performance.
- No heterogeneous communication overhead.
- Supports binarized networks, achieving over 800GOPS.
- 1MB on-chip SRAM supporting AI models with up to ~800kB tensor arena requirement.
- Weights stored in external flash memory. Large on chip memory maximizes AI model inference performance.
Easy to use
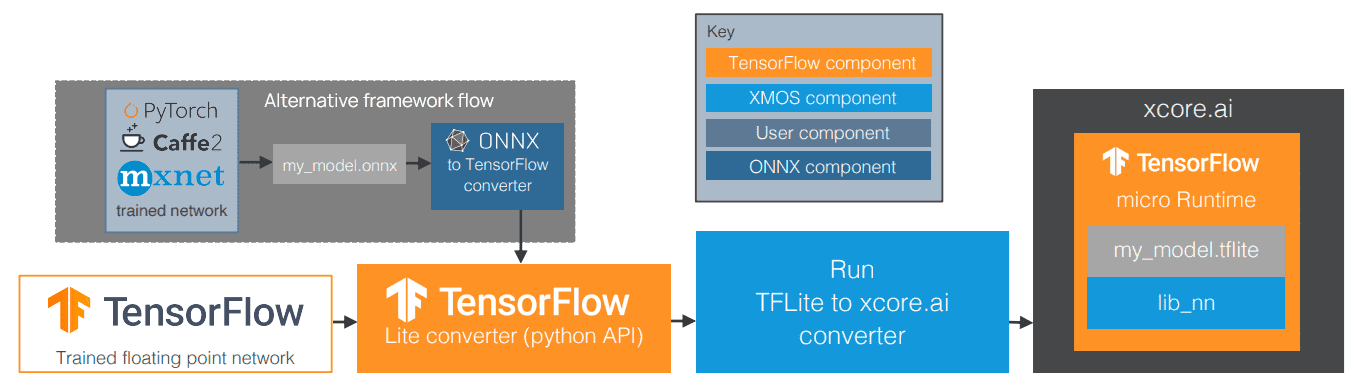
- XMOS AI Tools allow deployment of AI Models developed in Python-based environments like PyTorch and Tensorflow.
- Models are optimized for embedded use with Tensorflow Lite with high performance operators that exploit the XCORE.AI capabilities and minimize tensor arena sizes.
- Generated C code can be integrated with other embedded functions allowing XCORE.AI to efficiently handle image-based and audio-based applications.
- While most embedded AI apps use 8-bit quantization, XCORE.AI also supports binarized networks and larger datatypes (e.g., floating point) where needed.
Flexible & Scalable
- Unique design with 16 independent hardware threads per device
- Threads can be used independently or collaboratively.
- Supports a diverse range of functions, including; AI inferencing, signal conditioning, I/O and control
- High-speed communication between threads and between devices provides:
- Scalability of performance and memory.
- Concurrent implementation of high-performance inferencing alongside other functions
A.I. Workflow
Efficient data capture and processing with deep neural networks; inferencing and characterisation of 8bit, 16bit, 32bit and binarized network models are supported. Programmable in C with standard tools, and frameworks.
Other Capabilities
DSP
XCORE enables whole DSP systems to be built with the lowest system bill of materials, including significant DSP workloads in both fixed- and floating-point formats.
I/O
Designed to meet the demands of advanced applications in diverse industries, XMOS processors offer cutting-edge features and robust performance in handling I/O operations.
Control
XCORE® delivers in hardware, many of the elements that you’d expect to see in a real-time operating system (RTOS), but with 10ns per single cycle response to events